我们首先要清楚人工智能(Artificial Intelligence)是一个计算机领域的技术,直译过来它泛指人通过机器实现的智能。那么传统的计算机技术与人工智能有什么区别?下图是现在所有计算机鼻祖的模型,打孔机。
打孔机的原理很简单,在有关记忆的讨论中提到过:打孔机有一套基本的规则,根据不同的输入按照这个规则输出不同的结果,无论数据输入是什么样的,都不会影响基本的规则,那么现代计算机工作起来是什么样子的?
我们举个有趣的例子,如何判断一个人是不是秃头?
我们做一个基本的假设,一个人如果有5000根头发算不秃头,低于5000根算秃头,从现在的编程模式开始,写下的代码大致意思为:如果(if)头发大于等于5000根,那么不秃头;不然(else)小于5000根,那么秃头。
我们模拟遇到各种各样的问题,用语言模拟现在的编程方式解决问题的过程:
1 一个人如果掉了一根头发,那么算不算秃头?
为了弥补这个绝对化的答案,我们假设4900~4999的数据算不太秃。
2 如果掉的是脑袋后面的正面看不见怎么办?
为了弥补这个我们限定掉正面的算秃头。
3 如果是头顶很秃,外围很多的头发(谢顶)算不算秃头?
为了弥补这个我们把谢顶的算秃头。
4 如果一个人脑袋很大,5000根看起来很秃,如果脑袋很小,5000根头发看起来不少怎么办?
为了解决这一条,我们再加上一条,用头发除以头皮的面积,低于算秃头,高于不算。
5 狗的毛非常少,是不是有点秃?
计算机无法回答,因为基本预设是判定人的,我们得把狗的模型加进去,依次为了防止遗漏,还要把猫加进去,有毛的加进去,森林加进去......
这个过程中实际情况会发生各种超出简单预料的变化,程序员要不停的限制条件,给出解决的判定方法,计算机完全没有自主的智能,编程过程需要无穷无尽的补丁。
那么人是如何判断秃头还是不秃头?
第一点,输入的信息成为记忆,信息输入的同时改变处理信息的结构,参与我们对这个词的认知。我们小的时候看过几个秃头的图片或者真人,大人说这叫秃头,然后我们就知道头发少算秃。这样少一根头发,少正面的头发,谢顶,头脑大小的问题都通过记忆的对比得以解决。
第二点,我们将获得的概念进行迁移,用来形容其他事物。当语文课本里出现“山秃了”,我们自然而然明白秃是一个形容稀少的词,就学会了说“山秃了”,当然也就可以判断狗的毛是不是秃了。
第三点,潜意识中我们赋予秃方向性,而具有类似意义的“光”则没有,输入的视觉信息与文字“秃”相配合的场景,只有在从下而上生长的东西变得稀少时才可以使用,而这种相关性又是因为输入的视觉信息所携带的相关性导致的,“秃”与自下而上的相关性并未被意识察觉却被正确使用。可以说头发秃了,林秃了,但是不能说胡子秃了,树根秃了。
第四点,基于时间,我们可以根据记忆对未来进行推测和想象。我们看过春夏秋冬树叶的生长过程,就可以推测出秋天树会变秃。
人的智能可以非常灵活的处理各种疑问和问题,输入的信息本身带有特征,那么人的智能反过来用这个特征(信息中不同因素之间的相关性)处理这个信息,现在广为使用的人工智能技术就在这几点向人类的智能靠近,这种人工智能技术就是机器学习,这里的学习就是指通过数据学习,就像我们获得记忆的过程。人工智能既然是模拟生命的智能,那么最直接的方法就是模拟生物神经网络(Biological Neural Network,BNN),它形成的就是人工神经网络(Artificial Neural Network, ANN),简称神经网络。
构造一个人工神经网络
我们尝试用一个例子来说明生物神经网络和人工神经网络是怎么工作的,如何把苹果和香蕉识别出来?为了简化这个问题,我们从两个特征来描述苹果和香蕉,颜色和形状,限定为苹果是红色的圆形,香蕉为黄色的弯形。
这里有非常重要的一点,红色总是伴随圆形,黄色总是伴随弯形,这里存在一种相关性,当然这是由其生物性状决定的。
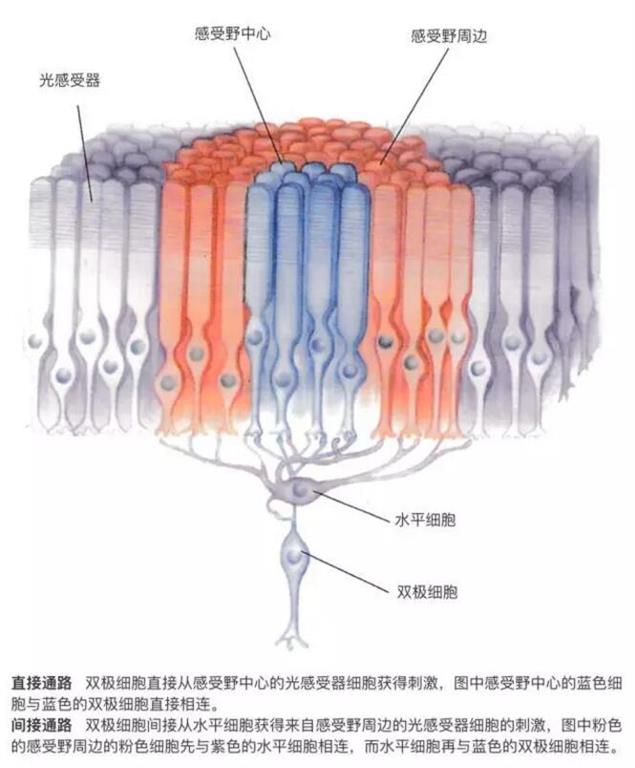
我们知道赫布的细胞集合,也了解了视觉感受野的基本原理。
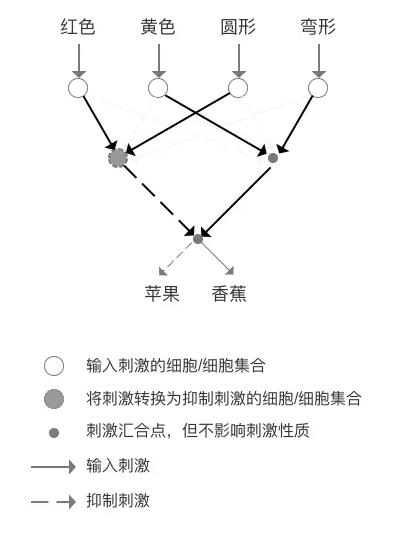
那么我们利用感受野的机制构造出一个识别苹果和香蕉的生物神经网络,如下图。
1.假象一个可以识别水果的生物神经网络
每个圆圈代表一部分工作的细胞或者细胞集合,深灰色的圆圈代表水平细胞,红色与圆形相当于感受野周边,黄色与方形相当于感受野中心,实线代表输入刺激,虚线代表抑制刺激,模拟的就是水平细胞的侧向抑制能力的结果,所以如果四个输入同时刺激的时候,刺激之和为0.
当出现红色并且为圆形的时候,刺激经过转换,这个网络会形成抑制刺激,判断为苹果;当出现黄色并且为弯形的时候,这个网络会汇合形成刺激,判断为香蕉。
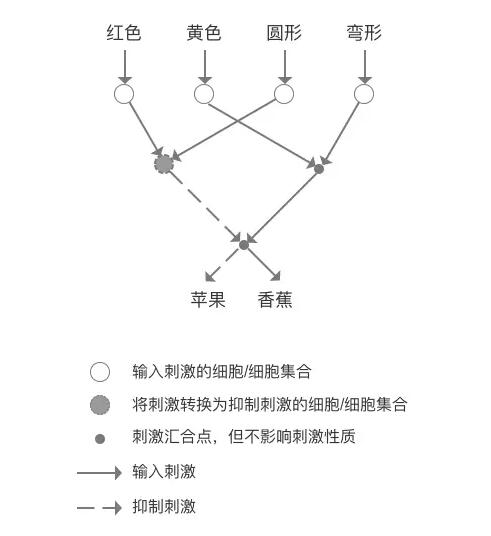
当然,这是我们的大脑明白了什么是苹果和香蕉之后的结果,那么在我们很小的时候没有见过苹果和香蕉的时候,生物神经网络的初始状态是什么样子呢?如下图。
2.初始的生物神经网络
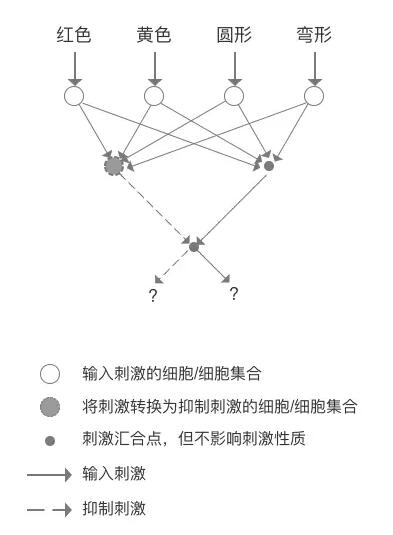
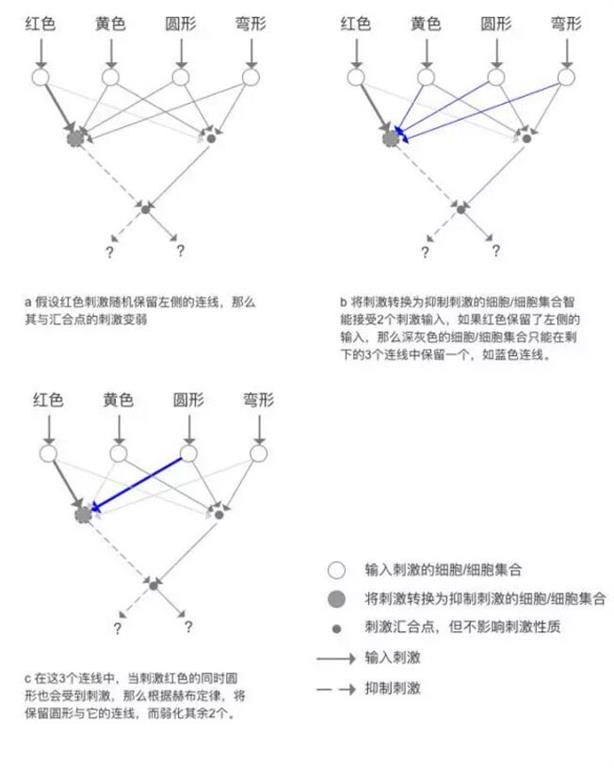
每个颜色的输入与传递刺激的汇合点还是抑制刺激的细胞都是相连的,形状也是一样,但是经过长时间的刺激学习,红色和圆形长期同时出现,通过各种各样的强化联系的方式,如细胞间争夺营养因子,或者突触容量的增减及突触重排,红色与圆形的联系被加强了,同样,黄色与弯形的线与汇合点的联系也被加强了,那么这个竞争的原理怎么表现呢?我们知道在上图的网络中从红色刺激触发的连线是2条,假设这个就是起始的突触容量,而最终要求的是是只有1条突触可以保存下来,同时无论是将刺激转换为抑制刺激的细胞/细胞集合,还是刺激集合点,从初始的4个突触容量最终要变化为最多可以容留2个突触作为进入的刺激,那么这个网络会形成什么样的呢?我们以苹果作为例子说明。
3.生物神经网络的学习过程
再加上香蕉的刺激,就会形成识别苹果和香蕉的生物神经网络,如下图。
假如一开始红色保留的是右侧的连线,那么形成的结果是正好相反的,但是并不影响区分二者的结果,这个过程省略,其结果如下图。
同时被刺激的连线被大大加强,而不被刺激的连线被削弱,生物神经网络经过反复刺激,修改神经间连接的方式,最终形成了识别水果的能力。那么这个过程,如果用计算机的数学方式,应该怎么表达呢?看下图。
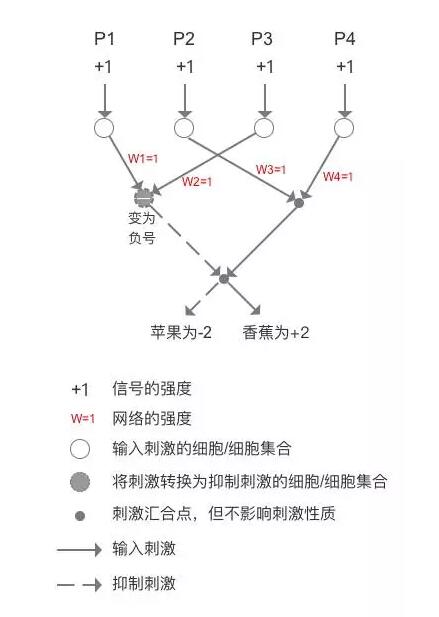
4 假象一个可以识别水果的人工神经网络
假设神经网络最终的输出强度为S,根据S的值判定是苹果还是香蕉,顶层细胞输入的信号强度为P,网络的强度为W,那么S = P1 x W1 + P2 x W2 + P3 x W3 + P4 x W4 。
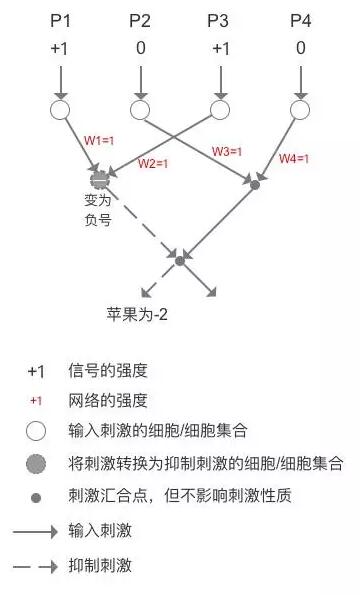
当我们看到苹果、红色和圆形刺激的时候,P1和P3为1,P2和P4的刺激为0,假设所有的网络强度一致,W1=W2=W3=W4=1,那么识别苹果的结果就是S = - ( 1 x 1 ) + ( 0 x 1 ) - ( 1 x 1 ) + ( 0 x 1 ) = - 2,注意P1P3输入变为负号的过程,如下图。
当我们看到香蕉、黄色和弯形刺激的时候,P2和P4为1,P1和P3为0,结果为+2,判定为香蕉,如下图。
关键点来了,我们知道生物神经网络一开始并不是可以直接判断出来哪个是苹果哪个是香蕉的,那么人工神经网络起始也是一样,如下图。
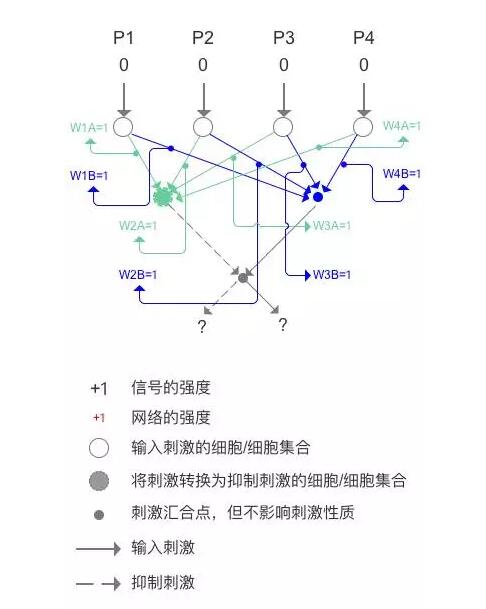
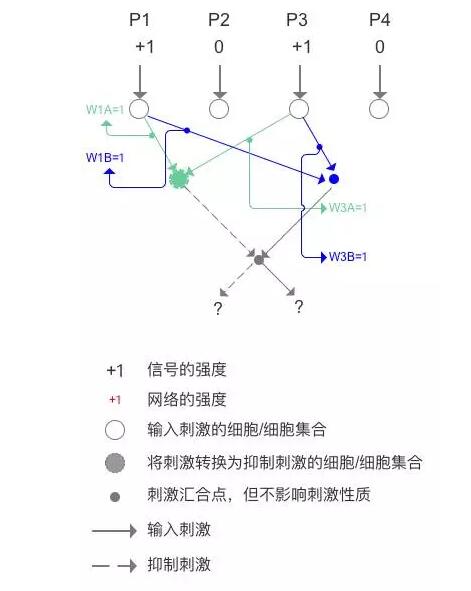
5 初始的人工神经网络
把转化刺激为抑制的细胞/细胞集合标记为绿色,把与它相连的线标记为绿色,用字母A表示与相关,网络强度为W1A=W2A=W3A=W4A=1;,把直接传递刺激的汇合点标记为蓝色,连线也标记为蓝色,用字母B表示相关,网络强度W1B=W2B=W3B=W4B=1,这样就是人工神经网络的起始样子。让我们计算一下不同刺激获得的值是多少,首先计算苹果,P1=P3=1,P2=P4=0不表示,如下图。
S1 = - ( P1 x W1A + P3 x W3A ) + P1 x W1B + P3 x W3B = - ( 1 x 1 + 1 x 1 ) + 1 x 1 + 1x1 = 0 , 计算完的结果是和事实不同的(应该得-2),正确的识别网络中蓝色的连线W1B和W3B的强度应该是0,那么这个网络就出现了误差。再计算香蕉,P2 = P4 = 1,P1 = P3 = 0 不表示,如下图。
S2 = - ( P2 x W2A + P4 x W4A ) + P2 x W2B + P4 x W4B = - ( 1 x 1 + 1 x 1 ) + 1 x 1 + 1x1 = 0,计算的结果一样不对(应该得+2),获得这样的结果并不意外,因为所有的网络强度大小都是相等的,好比生物神经网络的初始状态,我们要用数学的方法纠正这两个误差,实际上就是如何修正网络连接强度的值,达到学习的目的,这与生物强化某些细胞间的联系而弱化另一些的方法一致。
我们回到识别苹果的例子,假设识别苹果正确的值应该是-2,那么0的结果就出现了0 - ( -2 ) = 2 的误差(实际值减去正确值等于误差值),W1A为实际值,存在误差E1A,正确的W1A应该是W1A正确 = W1A - E1A(正确的等于实际值减去误差)= 1 - E1A,依此类推,W1B存在误差E1B,W3A存在误差E3A,W3B存在误差E3B。但是我们还是不能解决这个问题,能解决这个问题的关键是参照生物神经网络。
首先,对于S1正确的值而言,左侧细胞集合的输入在变号后是负数,而右侧节点的值为正数,那么左侧的绝对值一定要大于右侧的绝对值;第二点,无论左侧还是右侧获得的输入值是限定的最大值是2,这点是根据之前生物神经网络突触容量的假设所限定的;第三点,在这个设计的网络中,网络的强度不能是负值,但可以为0,所以W1B等的正确值大于等于0;那么我们用图来表示计算的过程,就会发现非常简单了。
最终的结果就是,与右侧相连的网络强度变为0,通过误差的反馈过程,数据训练了人工神经网络本身,当在此刺激P1,P3的时候,人工神经网络就可以正确识别出苹果来。在上述的例子中,为了模拟真实的生物神经网络中水平细胞的侧向抑制效果,特意加入了把左侧输入刺激变为负号的细胞集合,事实上当我们撤掉变号的过程,不限制刺激信号的正负,仍旧可以得到类似的结果。
我们并没有告诉人工神经网络什么是苹果或者香蕉,而只是输入数据和确定神经网络的基本连接规则(而非预先定义的直接规则),让人工神经网络自己学会识别出苹果,这就是人工神经网络与以往通过硬编码(如何识别秃头的例子)所不同的地方。
概念图
上面介绍了最为简单的人工神经网络,那么它与机器学习和人工智能的关系是什么?
人工神经网络是机器学习的一种技术,有关人工神经网络的我们了解了,那么不是人工神经网络的机器学习是什么呢?大数据这个词大家都不陌生,大数据技术依赖的是数据中的数据关系,通过大数据训练的算法中很多就是机器学习中不是人工神经网络的部分,比如根据你购物的时候购买特定商品的频率推送相应的广告。
除了人工神经网络,深度学习也是经常被提起的名词,人工神经网络与深度学习又是什么关系?我们首先要对人工神经网络有一个粗浅的了解,如下图。
在识别苹果和香蕉的例子中,我们构建的其实是趋近于两层的单层神经网络,甚至形成了部分侧向抑制的能力,如果四个输入信号都被刺激,那么最终的刺激为0。
人工神经网络有一个非常重要的部分,深度神经网络,是指含有多个隐层的神经网络,如下图。
依赖深度神经网络的机器学习被称为深度学习。深度神经网络本身有几个重要的类型:递归神经网络,卷积神经网络,前馈神经网络,这几种神经网络有不同的应用场景。深度学习又可以分为无监督学习和监督学习,如下图。
我们知道神经网络是要通过数据来训练(学习)的,所以如果先要通过具有相关性的标签化的数据训练网络,那么这部分数据就是通过人的监督来筛选的,比如我们构建的简单的识别水果的神经网络,就是先把苹果和香蕉的数据准备好,再输入进去,这就是监督学习。假如不去告诉人工神经网络什么是对,什么是错,什么是苹果,什么是香蕉,而是通过神经网络自己进行聚类学习,除了识别出一般的香蕉苹果,甚至发现特殊品种,这种就是无监督学习,或者叫非监督学习。
从人工智能到无监督学习,整体的概念联系图就是这样的。
人工神经网络的发展并非一帆风顺,从最早的单层神经网络到现在的多层神经网络经历了七十多年的研究,如下是人工神经网络的发展简史。
如下是人工神经网络可以解决的问题。
如下是人工神经网络所使用的算法。
我们继续简单了解一下深度神经网络在两个·领域的应用。
深度神经网络的两个应用领域
1.CNN—图像识别(参考 用CNN来识别鸟or飞机的图像)
在深度神经网络中,卷积神经网络(Convolutional Neural Network,简称CNN)是参考人的视觉形成规律所构建的,因此常常用于图像识别;循环神经网络,也被称为时间递归神经网络(Recurrent Neural network,简称RNN)是具有“记忆”的神经网络,因此常常用于联系上下文的语音识别,语义分析。
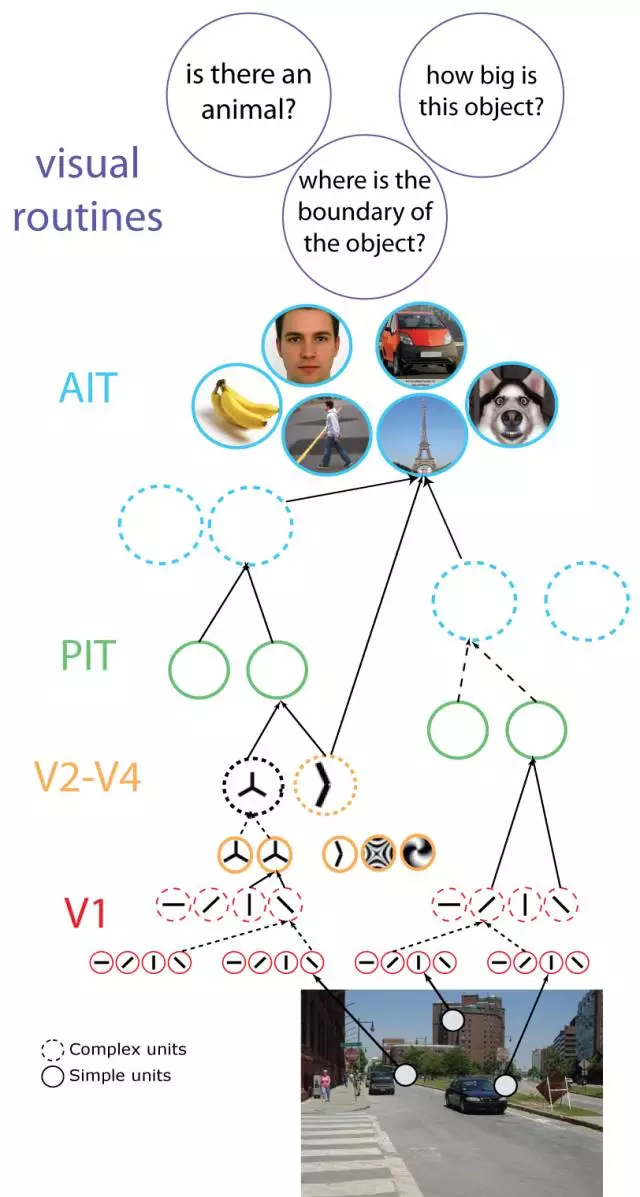
我们曾在讨论轮廓的时候见过下面的图片,它说的是人的视觉概念形成的过程。
视觉首先在V1形成基本的方向判断,然后逐层整合继续抽象,变成基本的纹理和小轮廓,最后形成轮廓概念,卷积神经网络与之类似,如下图。
在A部分神经网络形成一些简单的模式,比如其中的光条D,而在E部分神经网络形成了轿车的轮廓概念。图像识别的过程是通过数据集对神经网络进行训练,这包括监督学习和无监督学习,然后再用训练好的网络识别出轮廓概念。
2 RNN-语音/语义识别 (参考循环神经网络RNN打开手册)
语音识别与图像识别有两点不同,第一点,语音基本是一维的信息,语音识别以语调中的基本语素(最小的语音的声波频率)为主要识别信息,声音的大小和语气(声波的振幅)为辅,而图像识别是二维的平面信息;第二点,语音识别需要语境,通过上下文联系识别,这就需要“记忆”,而图像识别基本是即刻处理。RNN的特点就是“循环”,系统的输出会以某种形式会保留在网络里, 和系统下一刻的输入一起共同决定下一刻的输出,此刻的状态包“记忆”,变成下一刻变化的依据,如下图是几时卷积神经网络(CNN)与循环神经网络(RNN)的对比。
一对一的CNN针对的是一次性的数据处理,多对一的RNN中b1、b2、b3是神经网络主体不同时刻的状态,而a1、a2、a3又是不同的数据,只有c作为输出,这个多对一的过程可以应用在对一句话的分析上“他的眼睛流下了眼泪”,“他的”、“眼睛”,“流下了眼泪”可以相当于a1、a2、a3,“他很难过”可以相当于结果,如果没有对“他的”,“眼睛”的“记忆”,我们就没办法得出“他很难过”的结果,而且这种词汇的限定可以是不限长度的,如下图的场景。
“他拾起手帕,擦了擦流泪的眼睛,然后微笑”,这实际描述的是一个喜极而涕的场景,甚至我们可以揣测流泪者文雅举动背后的身份,只有将前后文联系在一起才能生成准确的语义,如果只断成“他拾起手帕”或者“他拾起手帕擦了擦眼泪”都会扭曲本来的含义。
3 CNN与RNN的融合
对于人机交互而言,信息输入的实质是编码和解码的过程,在计算机的早期阶段是键盘与晦涩的计算机语言,在之后图形界面出现,普通大众可以通过鼠标的点击表达自己的需求,再之后是移动时代,拖曳和多点触控出现了。那么现在,各种基于循环伸进网络技术的语音识别软件出现了,人机交互似乎可以回到人人之间的语音交互。科大讯飞在锤子手机发布会上出尽了风头,其依赖的技术是大很多语音识别技术并未采用的CNN,下图为其DFCNN。
简单的说,DFCNN就是把语音变成图形(将语音进行傅里叶变换后时间和频率作为维度),再用对图形处理更为熟练的CNN处理,获得更好的语音识别效果。
与之类似,搜狗语音识别也采用了CNN,如下图。
事实上,很多神经网络采用了复合结构,将CNN与RNN等神经网络模型整合之后进行应用。
数据与建模
我们知道深度学习所采用的技术关键点之一是通过数据训练网络,那么究竟需要多少数据?在2016年初,互联网出现了一个引爆性的新闻,谷歌收购的Deep Mind公司通过以CNN为基础的神经网络形成的人工智能Alphago在围棋上击败了李世石,在这个网络开始训练的时候已经相当于下了三千万的棋谱,而与李世石下棋的时候这个数据达到一亿,当然人类完成一局要一小时,而Alphago只要一秒。
Alphago的示例是不是说一定要海量的数据才能训练神经网络?这样对于没有大量计算资源(分布式的Alphago调用了1202个CPU和176个GPU),以及庞大数据库(3000万棋谱)的小公司和个人是不是就意味着无法使用人工智能?
有另一家公司在Deep Mind公司被收购前与其齐名,Vicarious,该公司的特点是大量借鉴神经科学家和脑科学家的科研成果进入人工智能领域,在其科研人员中有20%来自相关领域。我们在上文中提到了神经细胞的侧向抑制作用对轮廓识别和马太效应的影响,那么如果把这种能力模拟成神经网络中的某些函数会是什么结果?
Vicarious在NIPS、神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems)上发表了这样一篇论文,利用了脑科学上非常成熟的成果:人类的神经系统系统普遍存在的侧向抑制的现象,在他们在模型上实现了侧向约束(Lateral Constraints),如下图。
注意右下角的放大小图中的灰色方块一元因子(Unary factor),这是与水平细胞相似的关键。在字母验证码识别这个具体问题上,Vicarious基于生成型形状模型的系统能够只用1406张图片作为训练集,就超越了利用深度学习的800万图片达到的效果。
所以当模型足够优化的时候可以大大减少对数据的需求量,而借鉴神经科学的发展无疑是一个有效的途径。
迁移学习
传统的深度学习是以海量数据作为基础的,那么其后出现的就是增强学习。周伯通的左右互搏就像自己陪自己训练,Aiphago在训练神经网络的时候就是自己与自己下棋,这个就是增强学习的意义。除了深度学习和增强学习,还有一种学习方法被称为迁移学习(Transfer Learning)。
我们在创造的讨论中涉及到了迁移的概念,人类智能的特点之一就是将已经理解的抽象概念应用在广泛的领域,那么人工神经网络是不是也存在这样的能力?谷歌在谷歌翻译上应用了一个名为谷歌神经机器翻译(Google Neural Machine Translation,GNMT)的技术,就实现了类似人类的迁移学习能力。
我们知道翻译专业的人除了要学习第一外语,比如英语外,还要学习第二外语,比如日语,那么如果这个翻译是非常好的话,自然而然就可以充当日本人与英国人之间的翻译,尽管他的母语是汉语。这个翻译并没有直接学习日语翻译到英语的过程,但是他学习过中英与中日的翻译,在这个学习的过程中他形成了超越语言特征本身的抽象概念,然后这种概念在不同语言之间自由切换。
谷歌的翻译技术实现了部分迁移学习,而这种能力也是未来人工智能技术的必然之路。